

Introduction
This blog post is a HashiCorp Vault Monitoring Tutorial using Prometheus, Grafana, and Loki. Monitoring Vault is essential to ensure its availability, performance, security, and compliance. By collecting and analyzing metrics (Telemetry), system logs, and audit logs from Vault, you can troubleshoot issues, identify trends, detect anomalies, and enforce policies. Monitoring Vault also helps to optimize resource utilization, reduce costs, and improve user experience.
One way to monitor Vault is to use Prometheus for telemetry and metrics, Loki for system logs and audit logs, and Grafana for visualizing everything in a single pane of glass dashboard.
- Prometheus collects and stores metrics from Vault’s API endpoints, such as requests per second, latency, errors, and health status.
- Loki collects and stores logs from Vault’s server nodes, such as audit events, configuration changes, and errors.
- Grafana allows you to create dashboards that display the metrics and logs from Prometheus and Loki in a unified and interactive way. You can use Grafana to query, explore, alert, and analyze the data from Vault and gain insights into its performance and behavior.
Video
Below is a video explanation and demo.
Video Chapters
You can skip to the relevant chapters below:
- 00:00 – Introduction
- 01:22 – Explanation Animation
- 03:43 – Demo Starts
- 10:44 – View Grafana UI
- 15:57 – Create some Data Points
- 19:20 – Some References
- 21:22 – Configuration Walks-through
- 30:31 – Wrap Up
Pre-Requisites
You can run everything in GitHub’s codespaces. Just start a new codespace from the GitHub repo. If you don’t want to use codespaces, then you’ll need a Linux machine running Docker and Docker Compose. You will also need Vault installed.
Vault Monitoring Components
There are three main components when monitoring Vault. You can see them below along with the tool used to monitor them.
- Metrics/Telemetry -> Prometheus
- Operational Logs -> Promtail pushes to Loki
- Audit Logs -> Promtail pushes to Loki
Workflow
Now let’s take a look at a diagram to understand better the different tools that we will use to monitor Vault.
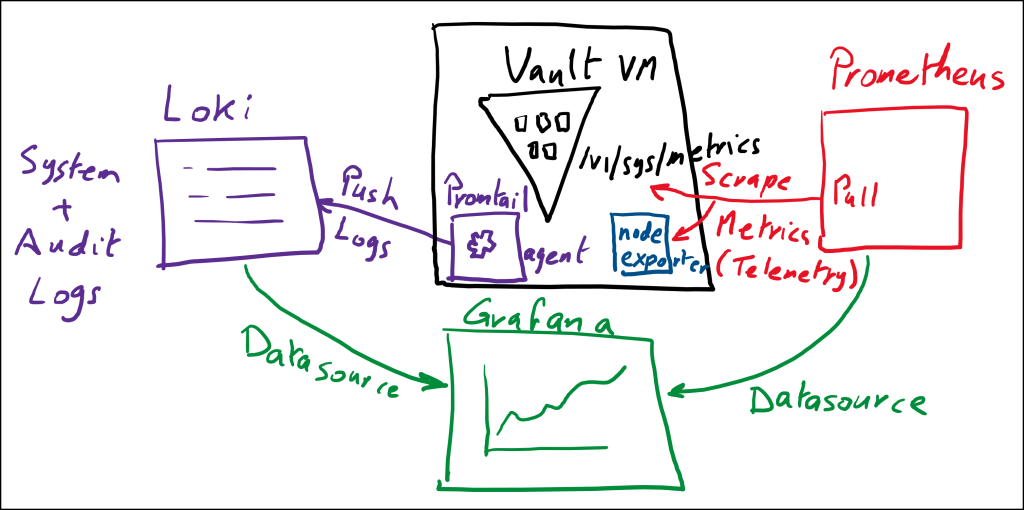
Vault Monitoring Workflow
-
Prometheus scrapes metrics (Telemetry) from the
v1/sys/metricsendpoint on Vault. -
Prometheus also scrapes metrics from the Vault VM using
node-exporter. Node exporter exposes operating system metrics such as CPU, memory, and disk utilization. -
Promtail is used as an agent that watches log files on the Vault VM and pushes these logs to Loki which is a log aggregator. Promtail watches two files:
vault.logfor system operational logsvault-audit.logfor Vault audit logs
-
Grafana is used as the presentation layer to view the metrics and logs in one place. You can create dashboards, alerts, and much more.
Configuration Review
Now let’s take a look at each one of our tools to see how to configure them properly.
Vault
Vault uses a configuration file and the main block that is needed here is the telemetry block. Take a look at this file below called server.hcl.
api_addr = "http://127.0.0.1:8200"
listener "tcp" {
address = "0.0.0.0:8200"
tls_disable = "true"
}
storage "file" {
path = "/workspaces/vault-monitoring/vault/data"
}
telemetry {
disable_hostname = true
prometheus_retention_time = "12h"
}
ui = true
disable_mlock = true
Prometheus
Prometheus is an open-source system for monitoring and alerting various aspects of cloud-native environments, such as Kubernetes. Prometheus collects and stores metrics as time series data, which are numerical measurements that change over time. Prometheus also supports labels, which are key-value pairs that provide additional information about the metrics. Prometheus uses a pull model to scrape metrics from HTTP endpoints exposed by instrumented jobs or exporters. Prometheus also provides a flexible query language called PromQL to analyze the collected data and generate alerts or graphs. Prometheus can be configured using a YAML file that specifies the global settings, the scrape targets, and the alerting rules.
This yaml configuration file is used to define the jobs for Prometheus to scrape. In our case, we have 2 main jobs to scrape:
- Vault metrics
- Node Exporter metrics
You can also scrape cadvisor. Cadvisor is used to expose container metrics for Prometheus to scrape. Below is the prometheus.yml configuration file.
# my global config
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# scrape_timeout is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'my-project'
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
- 'alert.rules'
# - "first.rules"
# - "second.rules"
# alert
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "alertmanager:9094"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: prometheus
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: cadvisor
scrape_interval: 5s
static_configs:
- targets: ['cadvisor:8080']
- job_name: vault
metrics_path: /v1/sys/metrics
params:
format: ['prometheus']
scheme: http
authorization:
credentials_file: /etc/prometheus/prometheus-token
static_configs:
- targets: ['host.docker.internal:8200']
- job_name: node-exporter
scrape_interval: 5s
static_configs:
- targets: ['node-exporter:9100']
Promtail
Promtail is a tool that collects logs from files and sends them to Loki, a log aggregation system. Promtail can be used for monitoring applications and systems by providing a unified view of the logs across different sources. Promtail can also enrich the logs with labels and metadata to make them easier to query and analyze. Promtail is designed to be lightweight and scalable, and can run as a daemon or a sidecar container in Kubernetes clusters.
In our case, Promtail is used to watch for certain files on a system and then push the content of these files to Loki. Below is the configuration file for Promtail called config.yml.
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: vault_audit_logs
static_configs:
- targets:
- localhost
labels:
job: auditlogs
__path__: /var/log/vault/vault-audit.log
- job_name: vault_system_operational_logs
static_configs:
- targets:
- localhost
labels:
job: systemlogs
__path__: /var/log/vault/vault.log
Loki
Loki is a tool for collecting and analyzing logs from various sources, such as applications, containers, or infrastructure. Loki is designed to be cost-effective, scalable, and easy to use. Loki allows users to query logs using a powerful query language, filter logs by labels or time range, and visualize logs in dashboards or alerts. Loki is compatible with Prometheus, Grafana, and other popular monitoring tools.
Loki also requires a configuration file and we called it loki-config.yaml. Check it out below.
#
# Documentation: https://grafana.com/docs/loki/latest/configuration/
#
# To make changes effective, restart Loki with:
#
# docker-compose restart loki
#
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
ingester:
wal:
enabled: true
dir: /tmp/wal
#
# How often to create checkpoints?
#
# I used to have this at 1 minute, but it was creating an insane amount of files
# which caused other performance problems. Feel free to tweak this.
#
checkpoint_duration: 5m
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
# Set this to allow faster startup
min_ready_duration: 5s
chunk_idle_period: 1h # Any chunk not receiving new logs in this time will be flushed
max_chunk_age: 1h # All chunks will be flushed when they hit this age, default is 1h
chunk_target_size: 1048576 # Loki will attempt to build chunks up to 1.5MB, flushing first if chunk_idle_period or max_chunk_age is reached first
chunk_retain_period: 30s # Must be greater than index read cache TTL if using an index cache (Default index read cache TTL is 5m)
max_transfer_retries: 0 # Chunk transfers disabled
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
storage_config:
boltdb_shipper:
active_index_directory: /tmp/loki/boltdb-shipper-active
cache_location: /tmp/loki/boltdb-shipper-cache
cache_ttl: 24h # Can be increased for faster performance over longer query periods, uses more disk space
shared_store: filesystem
filesystem:
directory: /tmp/loki/chunks
compactor:
working_directory: /tmp/loki/boltdb-shipper-compactor
shared_store: filesystem
limits_config:
reject_old_samples: true
reject_old_samples_max_age: 168h
ingestion_rate_mb: 64
ingestion_burst_size_mb: 64
chunk_store_config:
max_look_back_period: 0s
table_manager:
retention_deletes_enabled: false
retention_period: 0s
ruler:
storage:
type: local
local:
directory: /tmp/loki/rules
rule_path: /tmp/loki/rules-temp
alertmanager_url: http://localhost:9094
ring:
kvstore:
store: inmemory
enable_api: true
Grafana
Grafana is a popular open-source platform for visualizing and analyzing data from various sources. Grafana can be used for monitoring the performance, availability, and health of systems and applications. Grafana allows users to create dashboards with panels that display different types of charts, graphs, tables, and alerts. Grafana supports many data sources, such as Prometheus, Elasticsearch, InfluxDB, MySQL, and more. Grafana can also integrate with external services, such as Slack, PagerDuty, and email, to send notifications when certain conditions are met. Grafana is a powerful and flexible tool for monitoring and troubleshooting complex systems and applications.
You can provision dashboards and data sources in Grafana before running it. I found it problematic to provision dashboards ahead of time as you’ll run into issues related to data source IDs that need to be swapped out. A better solution is to import dashboards into Grafana after it’s up. You can use templates for the dashboards and Grafana will ask you for the data source you want to associate the dashboard with as you’re importing it.
# config file version
apiVersion: 1
# list of datasources that should be deleted from the database
deleteDatasources:
- name: Prometheus
orgId: 1
# list of datasources to insert/update depending
# whats available in the database
datasources:
- name: Loki
type: loki
access: proxy
orgId: 1
url: http://loki:3100
basicAuth: false
isDefault: false
version: 1
editable: false
# <string, required> name of the datasource. Required
- name: Prometheus
# <string, required> datasource type. Required
type: prometheus
# <string, required> access mode. direct or proxy. Required
access: proxy
# <int> org id. will default to orgId 1 if not specified
orgId: 1
# <string> url
url: http://prometheus:9090
# <string> database password, if used
password:
# <string> database user, if used
user:
# <string> database name, if used
database:
# <bool> enable/disable basic auth
basicAuth: false
# <string> basic auth username, if used
basicAuthUser:
# <string> basic auth password, if used
basicAuthPassword:
# <bool> enable/disable with credentials headers
withCredentials:
# <bool> mark as default datasource. Max one per org
isDefault: true
# <map> fields that will be converted to json and stored in json_data
jsonData:
graphiteVersion: "1.1"
tlsAuth: false
tlsAuthWithCACert: false
# <string> json object of data that will be encrypted.
secureJsonData:
tlsCACert: "..."
tlsClientCert: "..."
tlsClientKey: "..."
version: 1
# <bool> allow users to edit datasources from the UI.
editable: true
Docker Compose
We’re using docker-compose to run the monitoring stack. Below is the configuration that makes all the magic work. The file is called docker-compose.yml
version: '3.8'
volumes:
prometheus_data: {}
grafana_data: {}
services:
prometheus:
image: prom/prometheus
restart: always
volumes:
- ./prometheus:/etc/prometheus/
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
ports:
- 9090:9090
extra_hosts:
- "host.docker.internal:host-gateway"
depends_on:
- cadvisor
node-exporter:
image: prom/node-exporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- --collector.filesystem.ignored-mount-points
- '^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)'
ports:
- 9100:9100
restart: always
deploy:
mode: global
alertmanager:
image: prom/alertmanager
restart: always
ports:
- 9094:9094
volumes:
- ./alertmanager/:/etc/alertmanager/
command:
- '--config.file=/etc/alertmanager/config.yml'
- '--storage.path=/alertmanager'
cadvisor:
image: gcr.io/cadvisor/cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- 8080:8080
restart: always
deploy:
mode: global
grafana:
image: grafana/grafana
user: '472'
restart: always
environment:
GF_INSTALL_PLUGINS: 'grafana-clock-panel,grafana-simple-json-datasource'
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/:/etc/grafana/provisioning/
env_file:
- ./grafana/config.monitoring
ports:
- 3000:3000
depends_on:
- prometheus
loki:
image: grafana/loki:2.8.0
volumes:
- ./loki/config:/mnt/config
ports:
- 3100:3100
command: -config.file=/etc/loki/local-config.yaml
restart: "always"
promtail:
image: grafana/promtail:2.8.0
volumes:
- ./promtail/config.yml:/etc/promtail/config.yml
- /workspaces/vault-monitoring/vault/logs:/var/log/vault
ports:
- 9080:9080
extra_hosts:
- "host.docker.internal:host-gateway"
command: -config.file=/etc/promtail/config.yml
depends_on:
- loki
restart: "always"
Monitoring Dashboard
You can log into Grafana by opening a browser and going to http://localhost:3000. Use the username: admin and password: foobar.
Take a look at the screenshots below from the Grafana Dashboard monitoring Vault
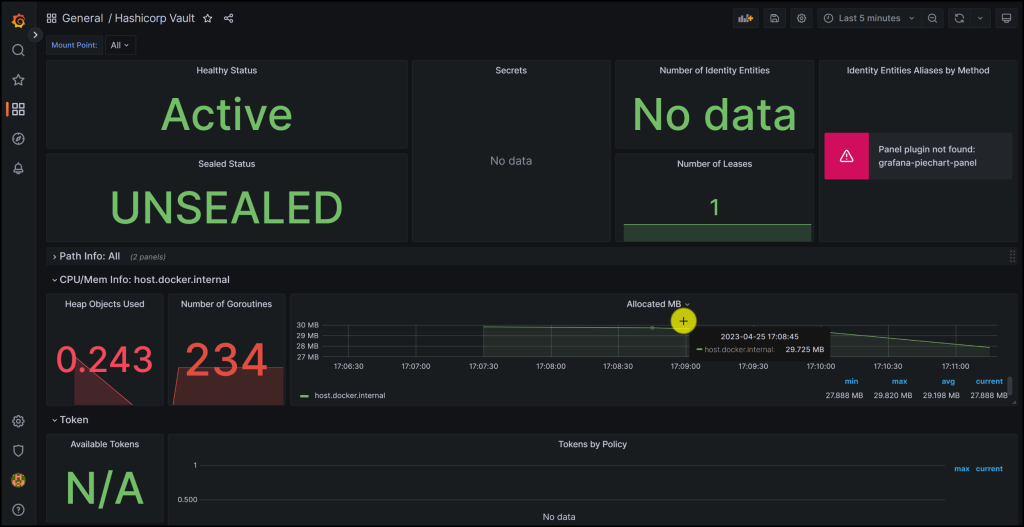
Vault Monitoring Dashboard in Grafana
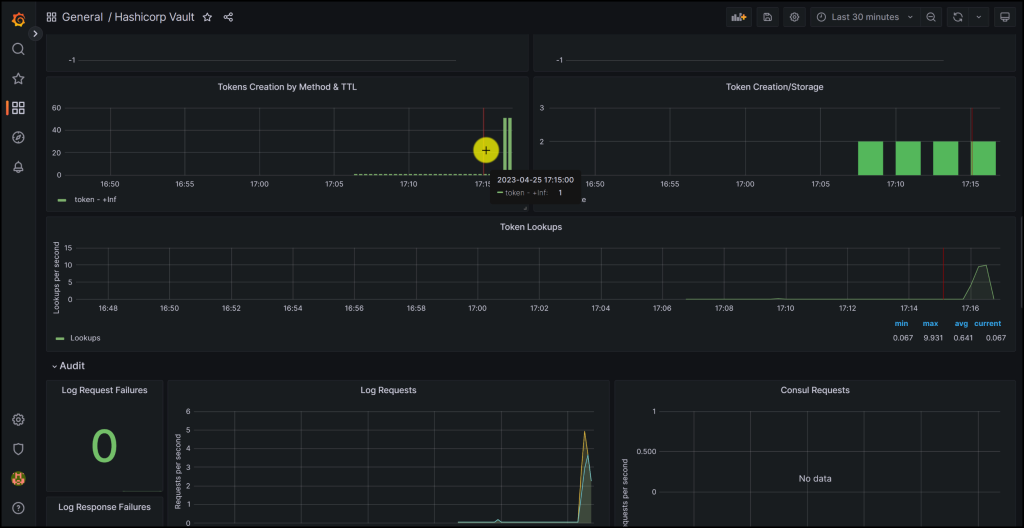
More metrics on the Grafana Dashboard for Vault
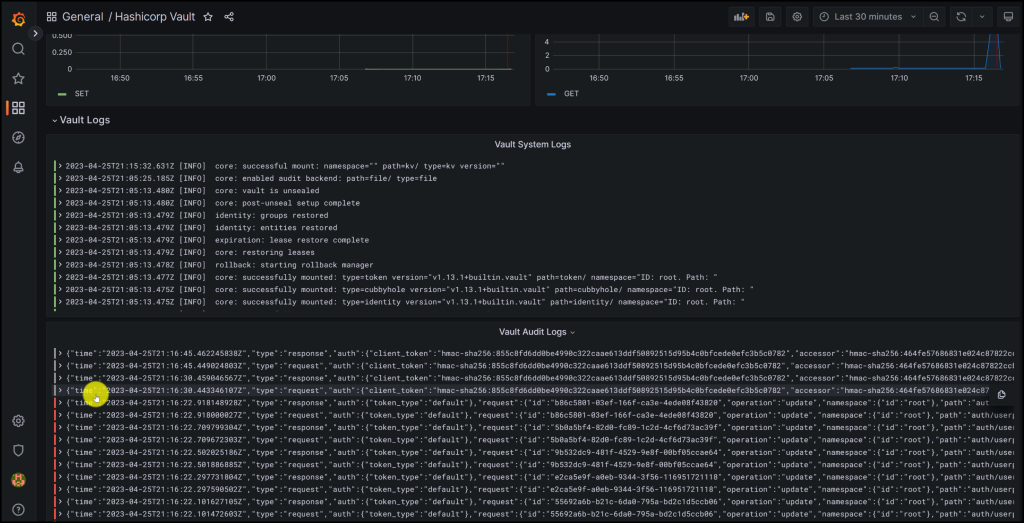
Vault System and Audit Logs in Grafana
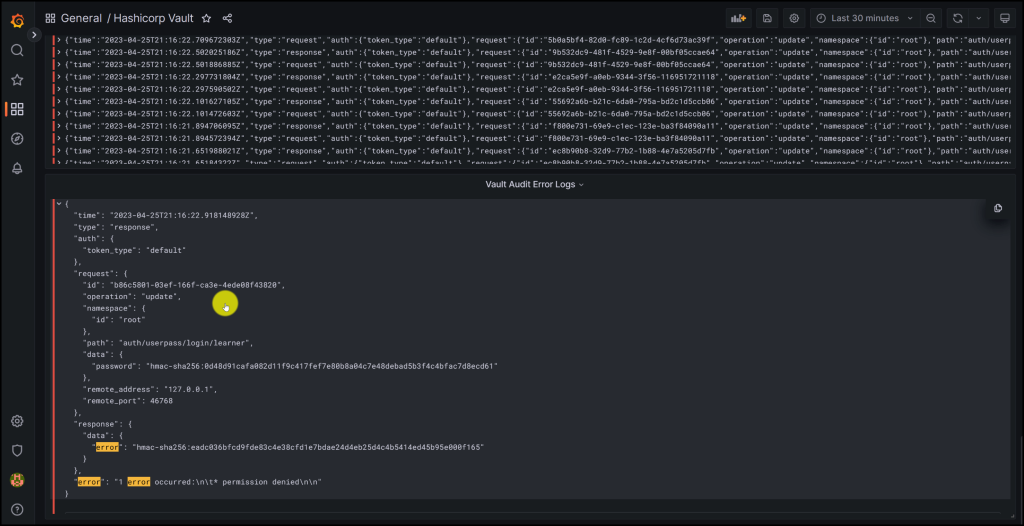
Filtering on Errors in Vault Audit Logs in Grafana
Conclusion
In this blog post, we have learned how to monitor HashiCorp Vault using Prometheus, Grafana, and Loki. These tools enable us to collect and analyze metrics, system logs, and audit logs from Vault and visualize them in a comprehensive dashboard. Monitoring Vault helps us to ensure its reliability, efficiency, security, and compliance. We have also seen how to configure Prometheus and Loki to scrape data from Vault’s API endpoints and server nodes, and how to create Grafana dashboards that display the data in a meaningful and interactive way. By monitoring Vault with Prometheus, Grafana, and Loki, we can gain valuable insights into its performance and behavior and improve our Vault operations.
References
- Monitor Telemetry with Prometheus & Grafana | Vault | HashiCorp Developer
- Telemetry Metrics Reference | Vault | HashiCorp Developer
Suggested Reading
- HashiCorp Vault Tutorial for Beginners
- HashiCorp Vault Backup and Restore Raft Snapshots from Kubernetes to AWS S3
- Migrate Secrets from AWS Secrets Manager to HashiCorp Vault with Python, Docker, and GitLab
- HashiCorp Vault API Tutorial and Pro Tips
- Unlock Hidden Perks in Your Backstage Software Catalog
Code
Hi and Welcome!
Join the Newsletter and get FREE access to all my Source Code along with a couple of gifts.